10Sep
Finance
Metastudio DRM Centralized Reference Data Management
Maintain valid reference data in a centrally managed solution and provide it to the whole organization for analytics, business processes parameters and data warehousing.
Reference Data a common element of descriptive, diagnostic and predictive analytics.
By combining historical data with the use of, versioned over time, reference data and metadata, you can perform diagnostic and predictive analyses without the risk of inconsistency.
Metastudio DRM the standard for reference data management in the Polish financial sector?
Almost 30% of the insurance sector and 25% of the banking sector in Poland use Metastudio DRM. Find out more about reference projects at leading financial institutions in Poland.
Data Governance with Metastudio DRM.
Using metadata and reference data versioning and change auditing, you get a complete data change path for audit purposes, historical and predictive reporting and categorization of data groups.
Metastudio supports the consolidation of HR data in the Medicover Group
 We have initiated a strategic partnership with Medicover, a pioneer in the field of private healthcare in Poland, introducing new data management capabilities. Our new project with Medicover, based on the Metastudio DRM platform, will revolutionize reference data management by introducing uniform standards and streamlining information flow. Thanks to its global reach and advanced technologies, our collaboration opens doors to new, innovative solutions in the areas of Finance and HR, enhancing efficiency on an international scale.
We have initiated a strategic partnership with Medicover, a pioneer in the field of private healthcare in Poland, introducing new data management capabilities. Our new project with Medicover, based on the Metastudio DRM platform, will revolutionize reference data management by introducing uniform standards and streamlining information flow. Thanks to its global reach and advanced technologies, our collaboration opens doors to new, innovative solutions in the areas of Finance and HR, enhancing efficiency on an international scale. Read more: Metastudio supports the consolidation of HR data in the Medicover Group
Reference data, metadata & data dictionaries right under powerful control
Issues and company challenges are the same everywhere. Hundreds of data dictionaries are being prepared by the business, usually as spreadsheet files. Then the files are attached to corporate emails and circulated from business owners to IT. Wrong versions or invalidated tables are being tested and implemented in business systems. Many unnecessary calls are needed to clarify issues and explain the meanings of dictionaries’ content, correct versions, or validity periods. Start managing reference data and metadata efficiently. Centralize their management, agree on their control and validation rules, start versioning them, and share them with other systems.
Watch now how to manage reference data with Metastudio DRM
The role of Metastudio DRM in organization.
MetastudioDRM enables import/export, storing, editing, managing, and integrating all data tables and dictionaries, and look-up tables across the organization in one place. It helps data professionals to save time and increase efficiency in managing the corporate DW, BI systems, controlling platforms, PMLs (product management lifecycle), client attributes, cost center indexes, etc. Metadata management was always challenging. Data democratization is entering a new era. The overall Metastudio enterprise data architecture presents in Fig. 1.
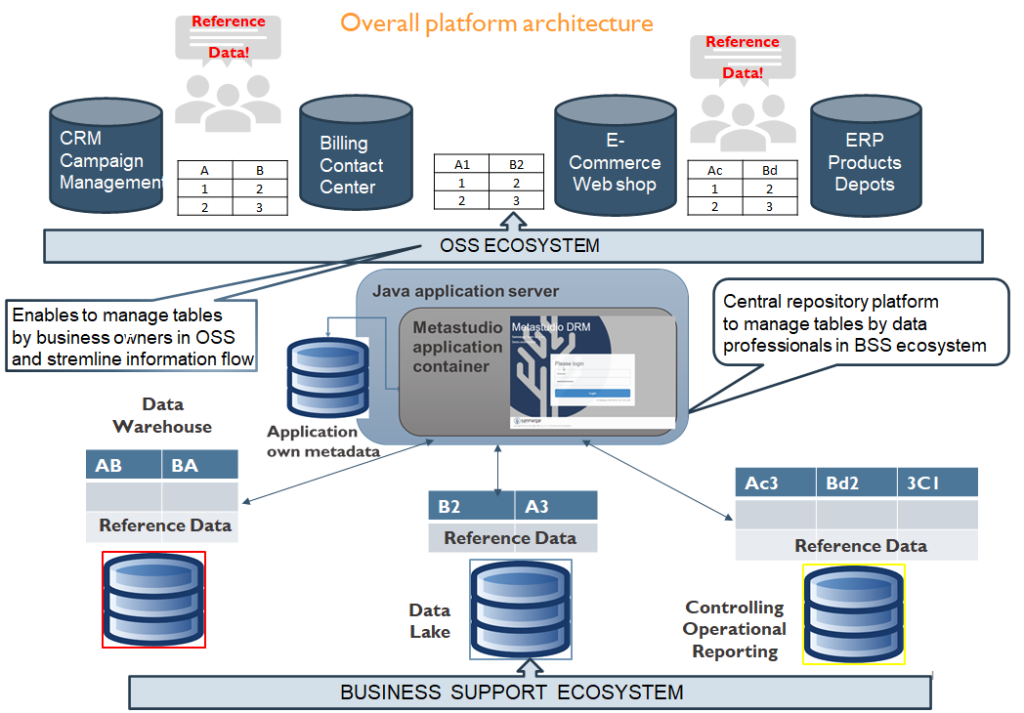
Quick benefits to your organization
- Get centralized control over RDM. RDM is a critical element of MDM. Dictionaries or look-up tables are everywhere in corporate architecture. Almost everyone uses these to make sense of data generated in organizations at different levels. Metastudio DRM gives single and centralized access and allows to control and manage all reference data in one place.
- Give one app to all users. All applications and transactional systems rely on reference data. Business and IT need to use the same data in every part of various systems.
- Streamline information flow between business and IT
Use Cases
Data migration & integration

Help data migration between various business applications. Reconcile and agree with dictionary data between old and new systems fast and efficiently. In particular required during data migration to newly implemented solutions like billing, CRM, ERP, etc. Also vital for data merger and integration between the existing systems and platforms. It is mainly dedicated to business users who can work with their data. They can map the application-specific codes to appropriate business glossaries. Data check validation and completeness rules are crucial functions for business users. A migration project manager is the primary beneficiary of the solution. We support ETL processes using various popular syntaxes like ANSI SQL, HiveQL, SAS4GL, InformaticaTL, and many more.
Data warehouse & reporting and BI

Metastudio DW & Reporting solution allows business users to manage and control reference tables and data dictionaries in conjunction with adequately implementing data processing in warehouses for appropriate information output across organizations. Metastudio supports users in defining glossaries, dimension tables, and their hierarchies for reporting purposes.
Data quality

Manage data quality in various business areas like DW, marketing campaigns, and financial and operational reporting. The solution uses parameterized, dedicated dictionaries to control data from the extraction and transformation to data load. Metastudio automatizes data fulfillment and its adjustment according to defined criteria in the required process.
Controlling and Accounting

MetastudioAccounting solution allows efficiently managing charts of accounts from various reporting perspectives. It enables users to join different data dictionaries and convert them to codes executing financial reports for multiple organizational stakeholders. Financial controlling and accounting can easily create mapping tables for data collection from analytical or main accounts and show results as economic meanings like the cost of goods sold, accounts receivable, inventory, and tangible or intangible assets. The solution also significantly helps to show income statements, balance sheets, and cash flow statements in different accounting standards: IAS vs. local regulations, IFRS vs. corporate standards, or country-specific rules. It is also beneficial for GL reconciliation template preparation, execution, and adjusting journal entries.
Supported technologies







Customer Success Stories
Key customers
The key task of the data warehouse at the Bank is to support processes related to mandatory reporting and risk estimation. Business requirements necessitate frequent changes to the data warehouse configuration. Metastudio DRM fully met this requirements and is an important element of the bank’s data warehouse architecture. This tool reduces the risk of introducing incorrect configuration by technical users and quickly determines who, when and what changes in warehouse parameters introduced and what consequences they had for the reporting data.
Metastudio DRM allows our business users intuitive work with dictionary data. This solution gives us the possibility to create advanced control schemes for entering data and to verify data warehouse configuration for a specific moment in time. An important feature for us is the validation of the syntax of automatically generated data loading processes.
Zdzisław Dec
Business Intelligence Office Director; BNP Paribas Bank SA
Business Intelligence Office Director; BNP Paribas Bank SA










